





在工作中,我们有时候会遇到识别图片里面的文字信息,比如姓名,验证码等,这里就要涉及一个OCR(Optical Character Recognition)的概念,即光学字符识别,简单讲就是对图片文件中的文字进行分析识别,获取的过程。
Tesseract是一个著名的开源OCR引擎,初期是由惠普实验室研发,后期开源,由Google改进优化升级。
Tess4J是对Tesseract OCR API 的Java JNA 封装。使java能够通过调用Tess4J的API来使用Tesseract OCR。支持的格式包括TIFF、JPEG、GIF、PNG、BMP、JPEG、PDF。
下面进行简单的使用吧。
1、新建一个maven项目,引入依赖
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.4.0</version></dependency>
2、准备测试代码
public class TestTess4jOCR {//语言库类型中文:chi_sim,数字加英文:engprivate static final String LANGUAGE = "eng";//语言库位置,里面目前只放了:chi_sim.traineddata(中文),eng.traineddata(英文)private static final String DATA_PATH = "F:\\Workspace\\eclipse_workspace\\tessdata";public static void main(String[] args) {byte[] imageByte =TestTess4jOCR.getImageBytes("F:\\2.jpg");TestTess4jOCR.testDoOCR_ImageByte(imageByte);}public static void testDoOCR_ImageByte(byte[] imageByte) {try {InputStream sbs = new ByteArrayInputStream(imageByte);BufferedImage img = ImageIO.read(sbs);ITesseract instance = new Tesseract();//设置语言库所在的文件夹位置,最好是绝对的,不然加载不到就直接报错了instance.setDatapath(DATA_PATH);//设置使用的语言库类型:chi_sim,eng 中文简体instance.setLanguage(LANGUAGE);String result = instance.doOCR(img);System.out.println("扫描的文本:"+result);} catch (Exception e) {System.err.println("扫描图片文本错误:"+e);}}public static byte[] getImageBytes(String path) {//图片转化为二进制byte[] imageBytes = null;try (FileInputStream fileInputStream = new FileInputStream(new File(path));) {imageBytes = new byte[fileInputStream.available()];fileInputStream.read(imageBytes);} catch (IOException e) {e.printStackTrace();}return imageBytes;}}
上面可以看到有一个语言库的概念。中文一般用:chi_sim.traineddata,数字和英文一般用eng.traineddata,更多tessdata语言库下载地址。
这里下载了chi_sim.traineddata和eng.traineddata用来测试。
3、测试
通过修改LANGUAGE和图片路径进行测试
第一组测试,数字识别: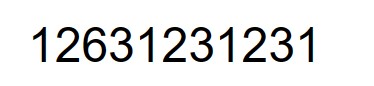
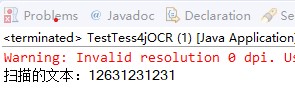
第二组测试,中文识别:

第三组测试,图片验证码:
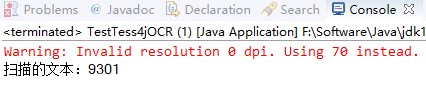
感觉功能好强大,完全不需要调用腾讯百度的接口!咱再试试

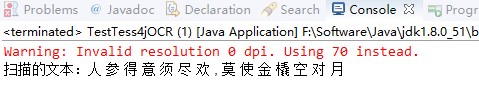

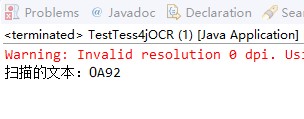
这,好吧,毕竟肯定没有付钱的好,当然我们还可以进行针对性的训练,当然这是后话!
