






在我看来,学习大数据最起码要有如下四项前提:
- 大数据知识体系
- 自己的大数据平台
- 大数据项目
- 阅读源码
大数据知识体系
首先,我们必须清楚的吗,明白自己学习大数据是要学什么东西,如果愣头青这里学一点那里学一点都不知道是干啥的,只会浪费很多时间。比如今天学一点Hadoop,明天学一点Spark,后天学一点flume没有系统的知识体系图是很抽象的,很难有高效益。
我们必须清楚的知道,各种大数据技术之间的区别和优缺点,为什么会有这项技术,比如Hadoop2明明都有MapReduce了,为何还需要Spark,Spark又有什么优点。学习Hadoop要学习那些内容,学习Spark又要学习哪些内容,为啥要掌握数学知识以及提高自己的英语水平,最后是否需要转人工智能。
所以,我们第一步一定要清楚的了解大数据的知识体系,以防在海量知识里迷失自己。
因为没有时间去系统的培训学习,所以我这边的大数据学习流程是,先学Hadoop,弄懂Hadoop的三大知识点:HDFS、Yarn、MapReduce。
然后学习Spark,弄懂Spark的源码,期间学习Scala语言的使用,因为Spark的源码就是scala写的。然后再去学习Hadoop的Hive,Hbase等等,流程大概这样子。
自己的大数据平台
学习大数据,必须有自己的大数据平台,因为搭建好环境是第一步,所以必须有一台电脑,然后安装虚拟机,搭建完全分布式环境来练习。当然有条件的可以用云服务器,或者多台电脑。
大数据项目
学习了大数据,必须要想办法去做项目,只有通过项目才能进一步的掌握大数据的使用,了解哪一些业务场景是可以用的.
阅读源码
如果说我们学习接口的调用的话,那么很简单,但是作为一个大数据工程师,必须知道原理,所以我们必须去阅读源码,像Hadoop就是java写的,Spark就是scala写的,我们要去专研源码。
当然这个过程中,我们要去提高我们的数据结构算法分析能力以及英语水平。
好啦,下面给出一张大数据知识体系图:
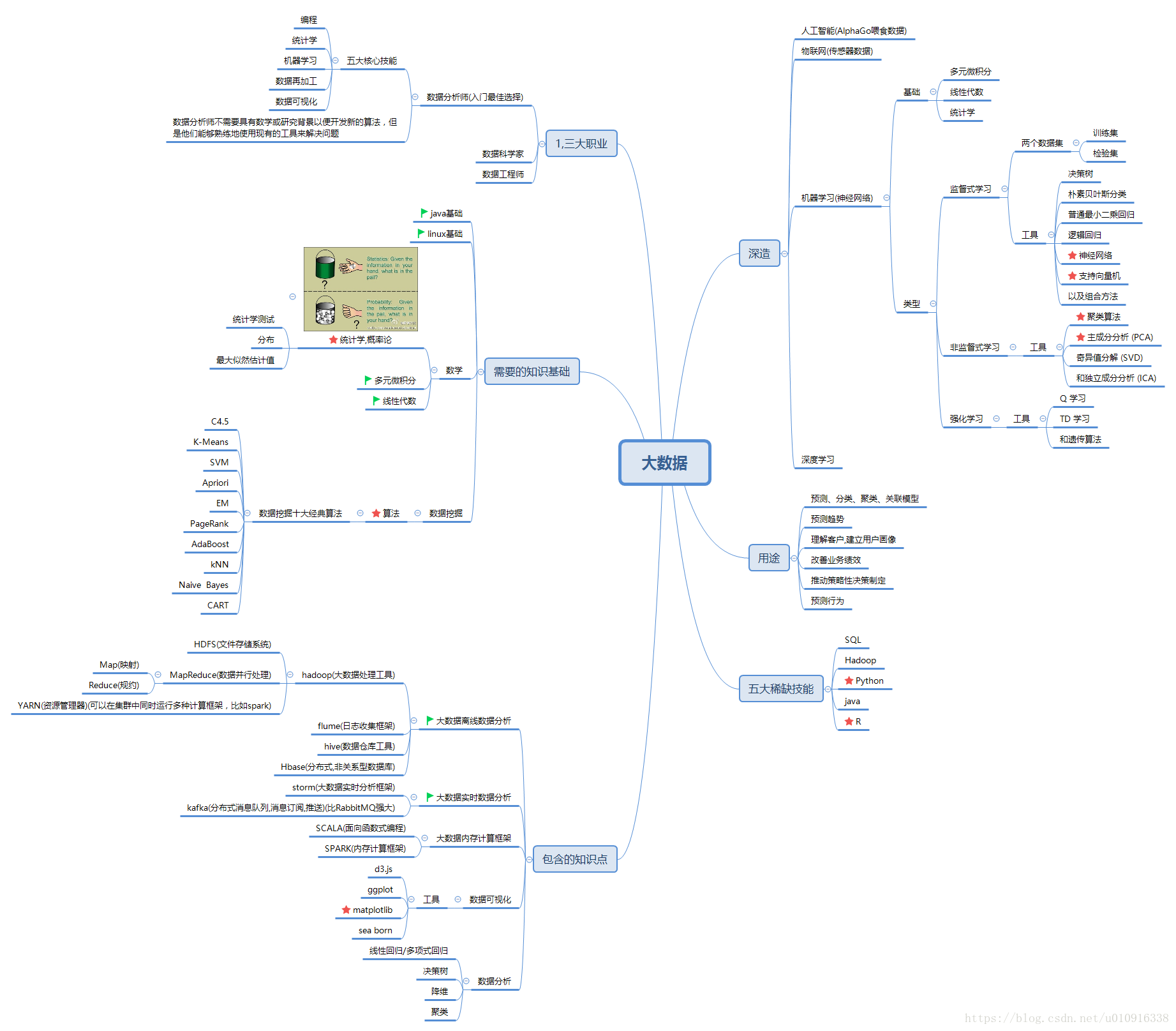
路漫漫其修远兮 吾将上下而求索!
