





Spark环境的搭建相比于Hadoop集群的搭建还是比较简单的,而且跟Hadoop集群的搭建流程也很相似,只是没有Hadoop集群那么多的配置文件要修改。本文中,我将详细介绍Spark的本地模式、Standalone模式(伪分布)、Standalone模式(全分布)、Yarn集群模式的搭建。
准备工作
Spark运行模式了解
搭建之前,我们得了解Spark运行模式的种类,有如下四种:
Local:多用于本地测试,如在eclipse,idea中写程序测试等。
Standalone:Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
Yarn:Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
Mesos:资源调度框架。
其实一般来说,我们的Spark都是运行于yarn上,并且文件系统一般是从hadoop的hdfs中读取,我这篇文章只会搭建local,standalone(伪分布式),Standalone模式(全分布),Yarn集群模式。
Hadoop完全分布式搭建
因为最后是搭建yarn集群模式,所以准备工作之前必须先搭建hadoop完全分布式。而在hadoop完全分布式中我这边hi安装好了jdk的环境以及各个节点的免密登录,具体大家可以参考我的博文:最小化CentOS7系统安装完全分布式hadoop-2.8.5,其实前面这一步还介绍了虚拟机的安装,网络的配置等等,可能需要费一点时间。
Spark下载
下载spark其实是跟hadoop包对应的,但是我看官网上的都是hadoop2.7 ,而我的hadoop安装的版本是最新版本的2.8.5应该也不影响。
访问官网:http://spark.apache.org/ 点击Download下载最新版本。
我这里下载完后是一个叫做:spark-3.0.0-preview-bin-hadoop2.7.tgz的jar包。
下面咱们就开始搭建各种运行模式下的Spark吧。我这里后面搭建的模式都是基于前面的模式的基础上进行的,比如我这篇第一种模式也是基于hadoop全分布式模式的基础上来搭建的。上面环境最备好后我这边会有三台机器:worker1、worker2、worker3用户为hadoop,并且都开启了免密登录。
搭建环境:CentOS7+jdk8+Hadoop2.8.5+Spark3.0.0
一、Local本地模式
1、用hadoop用户上传Spark下载包到家目录然后解压
tar -zxvf spark-3.0.0-preview-bin-hadoop2.7.tgz
2、切换root在/etc/profile中添加如下内容
我这里习惯添加环境变量都用root用户来,并且添加到/etc/profile中,当然你也可以直接添加到hadoop用户的~/.bashrc中。
su rootvi /etc/profile
内容如下
export JAVA_HOME=/usr/lib/jvm/jreexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/tools.jarexport HADOOP_HOME="/home/hadoop/hadoop-2.8.5"export SPARK_HOME="/home/hadoop/spark-3.0.0-preview-bin-hadoop2.7"export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$PATH
其实这里主要是添加SPARK_HOME以及PATH上面加入$SPARK_HOME/bin,当然sbin也可以加上,我这里就没有加了。
重新加载资源文件:
source /etc/profile
3、测试Local本地模式
没错,当这里,Local本地模式就配置成功了,不需要修改任务配置文件。
测试运行样例
run-example SparkPi 10
可以看到正常计算成功。
测试shell
spark-shell
二、Standalone模式(伪分布)
在搭建完Local模式后,这里来搭建伪分布的模式,在上面的基础上只需要修改Spark的配置文件spark-env.sh即可。
1、修改配置文件spark-env.sh
cd spark-3.0.0-preview-bin-hadoop2.7/conf/cp spark-env.sh.template spark-env.shvi spark-env.sh
在最下面添加:
# worker1是主节点,即本机的主机名export SPARK_MASTER_HOST=worker1# 默认端口号为7077export SPARK_MASTER_PORT=7077
2、启动集群测试
这里因为没有加上sbn的环境变量,所以要进入目录中执行。
cd /home/hadoop/spark-3.0.0-preview-bin-hadoop2.7/sbin
启动Master
./start-master.sh
启动slave
./start-slave.sh spark://worker1:7077
3、检查启动情况
jps
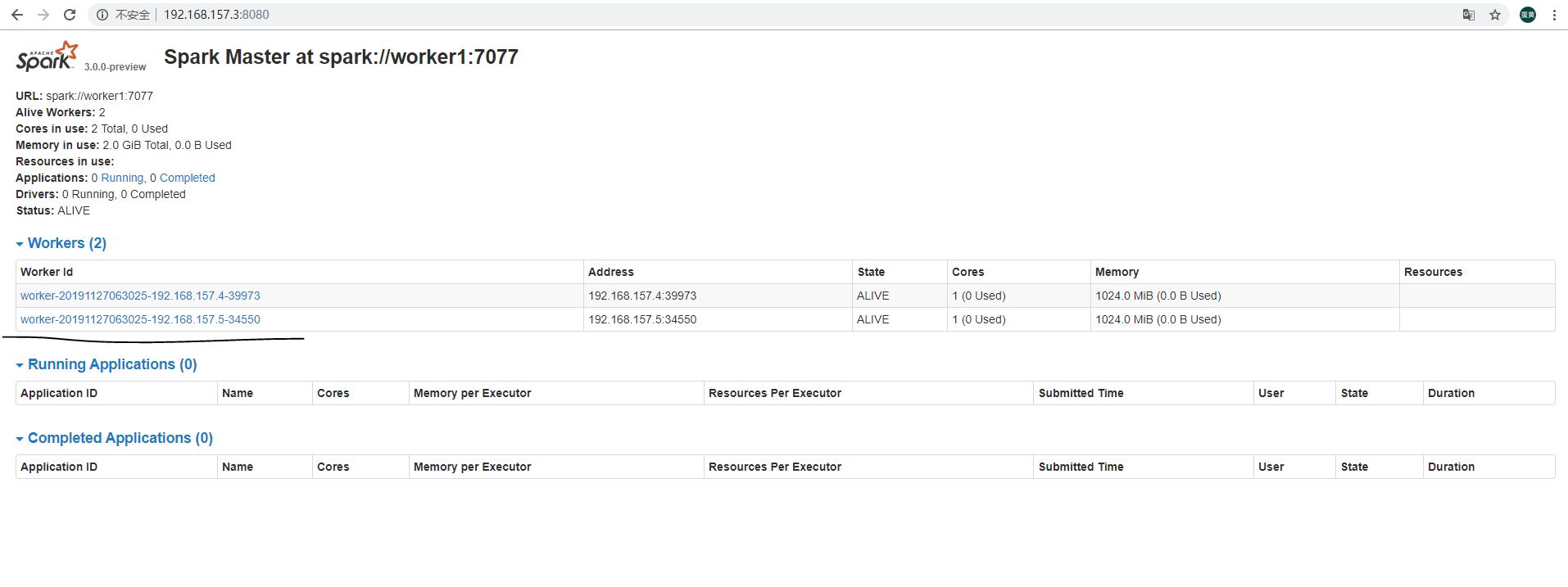
4、查看集群资源界面
浏览器访问:http://192.168.157.3:8080/
5、进入集群的shell
spark-shell –master spark://worker1:7077
三、Standalone模式(全分布)
上面的伪分布式就相当于在一台机器上跑,而全分布式就得涉及另外两台机,其实也超级简单的,因为我们在准备阶段已经让hadoop用户在worker1,worker2,worker3上免密登录了,所以只需要在伪分布式的基础上做如下修改。
1、修改配置文件slaves
cd /home/hadoop/spark-3.0.0-preview-bin-hadoop2.7/confcp slaves.template slavesvi slaves
删除原有节点,添加从节点主机名
worker2worker3
注意:这个很hadoop的配置文件修改是有区别的,这里不用指定主节点也就是master.
2、将整个spark目录发送到worker2和worker3两个从节点
scp -r /home/hadoop/spark-3.0.0-preview-bin-hadoop2.7 worker2:/home/hadoop/scp -r /home/hadoop/spark-3.0.0-preview-bin-hadoop2.7 worker3:/home/hadoop/
3、启动集群
cd /home/hadoop/spark-3.0.0-preview-bin-hadoop2.7/sbin
启动Master
./start-master.sh
启动slave
./start-slaves.sh spark://worker1:7077
4、查看启动是否成功
jps
5、查看集群资源界面
浏览器访问:http://192.168.157.3:8080/
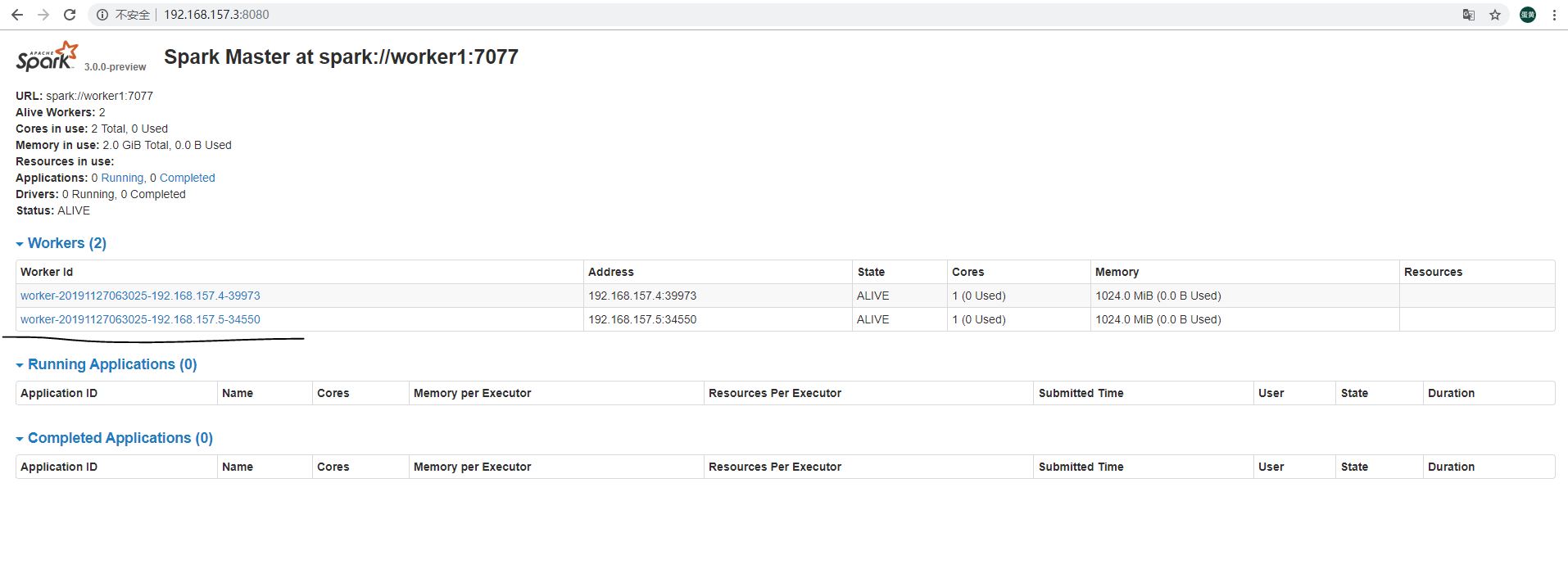
6、进入集群的shell
spark-shell –master spark://worker1:7077
四、Yarn集群模式
1、修改配置文件
在第三部全分布式模式下搭建yarn集群模式超级简单,只需要在spark-env.sh配置文件加入如下内容即可。
# 添加hadoop的配置目录export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.8.5/etc/hadoop
节点worker2和worker3都做一样的修改,也可以worker1修改完spark-env.sh后scp同步即可。
2、启动集群测试
启动yarn
因为我们已经是搭建好了hadoop全分布式集群,所以直接启动即可。
start-yarn.sh
启动spark集群
cd /home/hadoop/spark-3.0.0-preview-bin-hadoop2.7/sbin
启动Master
./start-master.sh
启动slave
./start-slaves.sh spark://worker1:7077
3、查看是否启动成功
jps
4、查看集群资源页面
5、进入集群的shell
spark-shell –master yarn
结束!
