







这里介绍如何安装Hadoop的伪分布式,步骤如下:
一、准备工作
参考我的博文 安装VMware15、CentOS7镜像官网下载、VMWare安装CentOS7超全图解、最小系统Centos7进行网络配置以及 ifconfig和vim的安装等博文安装好虚拟机,以及用远程连接工具S额cureCRT可以连接到虚拟机上传下载文件。
1、安装java
可以选择上jdk官网下载jdk包,解压后将路径加入环境变量,这里直接用如下命令安装。
yum install -y java-1.8.0-openjdk.x86_64
2、添加环境变量
echo 'export JAVA_HOME=/usr/lib/jvm/jreexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/tools.jar' >> /etc/profilesource /etc/profile
3、关闭防火墙
systemctl stop firewalld.service #停止firewallsystemctl disable firewalld.service #禁止firewall开机启动
4、关闭selinux
打开 /etc/sysconfig/selinux 文件把 SELINUX=enforcing 改为:SELINUX=disabled。
5、设置Hostname
我把机器的Hostname设置为worker1,并在/etc/hosts里添加Hostname指向内网IP。
hostnamectl set-hostname worker1echo '192.168.157.3 worker1' > /etc/hosts
二、搭建hadoop-2.8.5伪分布式环境
1、创建hadoop用户
useradd hadooppasswd hadoop
2、设置hadoop用户免密登录
hadoop用户登录
cd /home/hadoopssh-keygen
cat命令输出Key,写入到/home/hadoop/.ssh/authorized_keys中,并设置权限,用于机器自己登录自己:
cat /home/hadoop/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 600 ~/.ssh/authorized_keys
测试登录
ssh worker1yesexit # 退出刚登录的hadoop会话
3、下载hadoop-2.8.5并上传到hadoop用户根目录
hadoop用户根目录这里是/home/hadoop
去Hadoop的官方网站上选择安装包:https://hadoop.apache.org/releases.html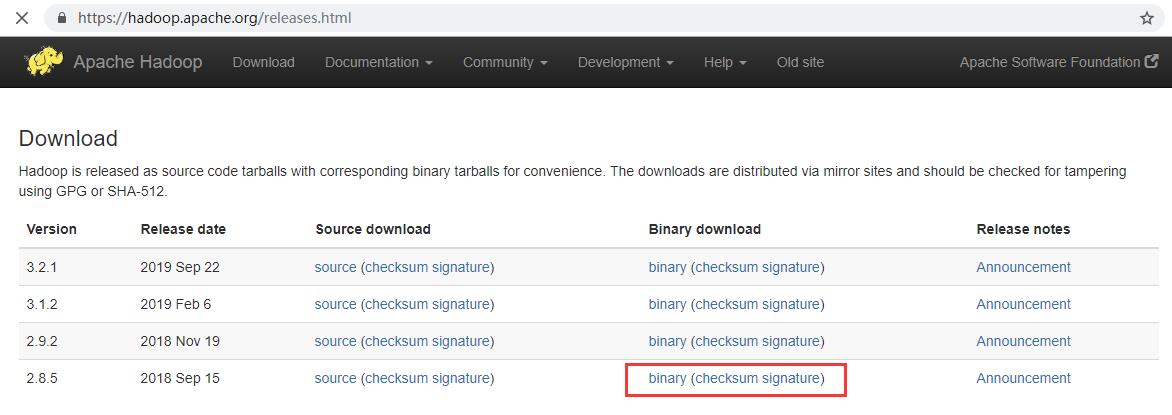
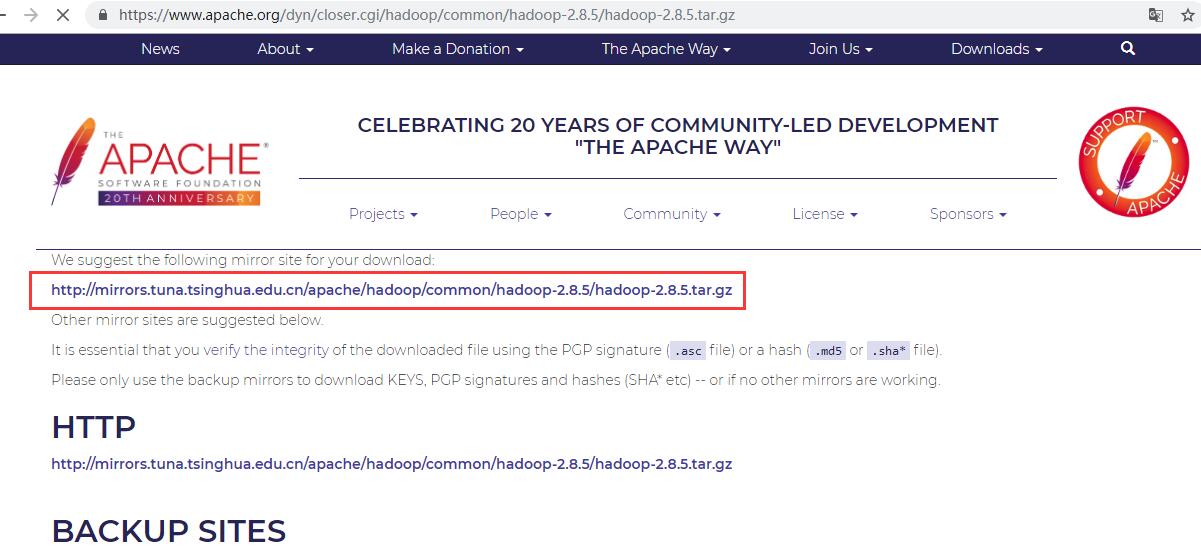
上传的话这里借助WinSCP工具,本人觉得贼好用。
4、解压并配置环境变量
切换到hadoop用户(su hadoop)
cd ~tar -zxvf hadoop-2.8.5.tar.gz
切换回root,配置环境变量
exitecho 'export HADOOP_HOME="/home/hadoop/hadoop-2.8.5"export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH' >> /etc/profilesource /etc/profile
5、hadoop配置文件添加JAVA_HOME环境变量
切换到hadoop用户
su hadoop
在如下两个文件第一行添加JAVA_HOME=/usr/lib/jvm/jre
${HADOOP_HOME}/etc/hadoop/hadoop-env.sh${HADOOP_HOME}/etc/hadoop/mapred-env.sh
6、修改core-site.xml、hdfs-site.xml 配置文件
# core-site.xmlecho '<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>fs.defaultFS</name><value>hdfs://worker1:9000</value><description>设定namenode的主机名及端口</description></property><property><name>io.file.buffer.size</name><value>131072</value><description> 设置缓存大小 </description></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/hadoop-2.8.5/tmp</value><description> 存放临时文件的目录 </description></property><property><name>fs.checkpoint.period</name><value>3600</value><description> 检查点备份日志最长时间 </description></property><property><name>hadoop.security.authorization</name><value>false</value></property></configuration>' > ${HADOOP_HOME}/etc/hadoop/core-site.xml# hdfs-site.xmlecho '<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>1</value><description>分片数量</description></property><property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/name</value><description>命名空间和事务在本地文件系统永久存储的路径</description></property><property><name>dfs.blocksize</name><value>134217728</value><description>HDFS块大小128M,如果你只有普通网线,就别64M了,没什么用</description></property><property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/data</value><description>DataNode在本地文件系统中存放块的路径</description></property></configuration>' > ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml# slavesecho 'worker1' > ${HADOOP_HOME}/etc/hadoop/slaves
上面分片数量是1,是因为我们是伪分布式只有一个节点,如果是有多个节点那么最好配置为3,这样的话会更高可用。
三、格式化
mkdir -p ${HADOOP_HOME}/tmphdfs namenode -format
四、启动测试
start-dfs.shstart-yarn.sh # 可选,暂时不启动没问题
浏览器访问:http://192.168.157.3:50070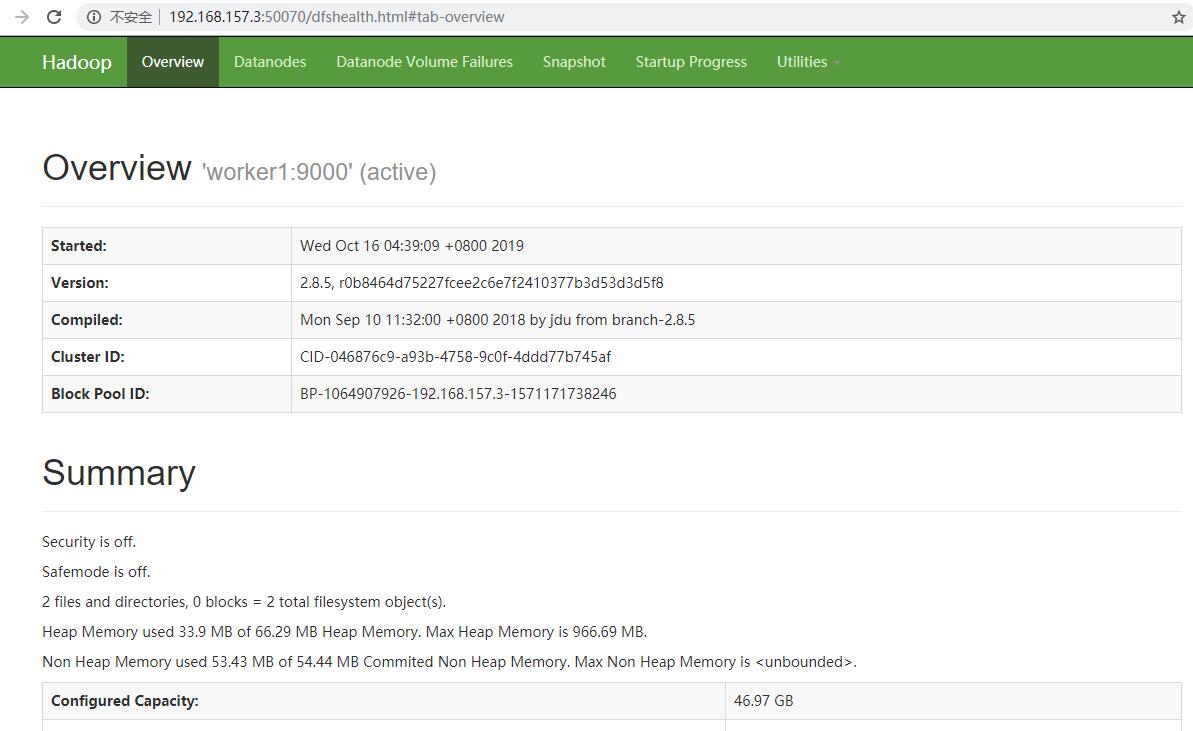
上传文件
mkdir text.txthdfs -put text.txt /
浏览器访问http://192.168.157.3:50070 点击Utilities->Browse the file system 可以看到已经上传了一个文件: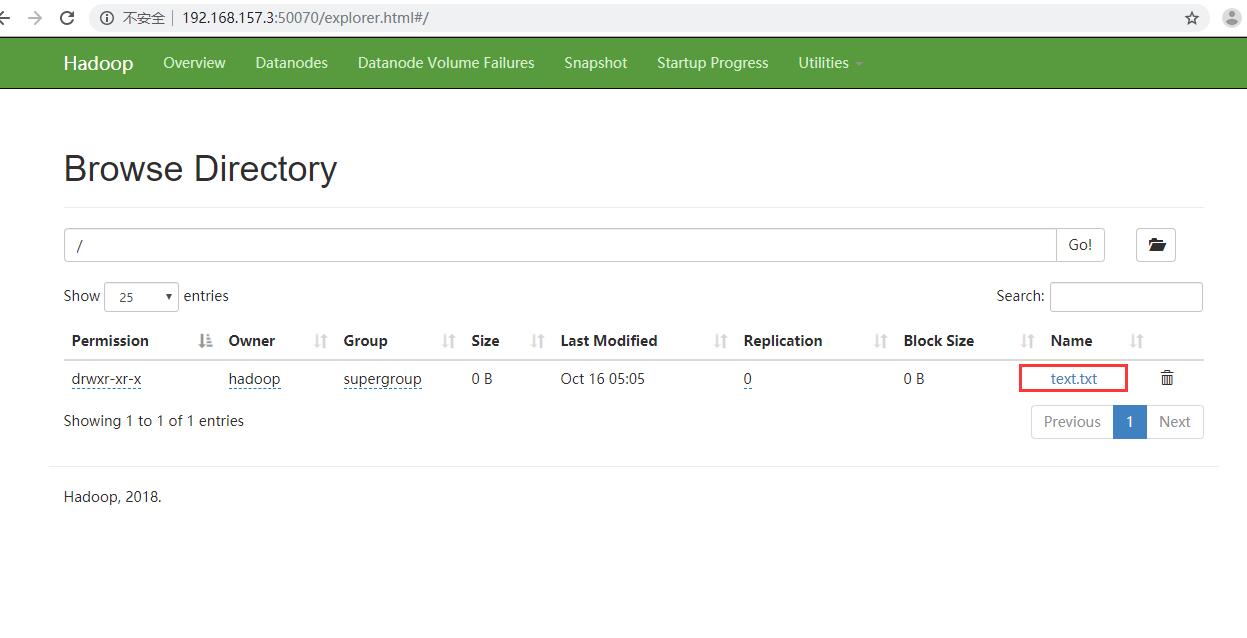
到此,伪分布式环境搭建成功。
