






我们在 最小化CentOS7系统安装伪分布式hadoop-2.8.5篇博文中已经成功搭建了Hadoop2.8.5的伪分布式环境,这里我们要在该环境的基础上搭建一个有三个节点的完全分布式环境,教程如下.
一、准备三台虚拟机
因为每一台虚拟机都需要搭建jdk、hadoop、关闭防火墙、禁用selinux,所以这里直接克隆上一篇博文中搭建的伪分布式环境。
1、关闭虚拟机
这里因为是完全克隆,所以需要关闭虚拟机。
2、完全克隆两台虚拟机
接下来选择完全克隆即可,连续克隆两台。
3、修改ip地址
因为是克隆的,所以需要去修改ip地址,我这边用的是NAT模式连接,所以直接去修改配置文件然后重启即可。
vi /etc/sysconfig/network-scripts/ifcfg-ens33
然后将IPADDR修改为新的IP,我这里三台机的IP分别是:
192.168.157.3192.168.157.4192.168.157.5
重启。
4、设置hostname
分别在每台机下面执行如下语句,主机名分别叫做worker1、worker2\worker3
hostnamectl set-hostname worker1hostnamectl set-hostname worker2hostnamectl set-hostname worker3
5、把每个节点的Hostname相互指向到ip,覆盖原文件
三台机都执行如下语句
echo '192.168.157.3 worker1192.168.157.4 worker2192.168.157.5 worker3' > /etc/hosts
到这里,三台装有jdk和hadoop的环境就搭建好了,接下来开始搭建完全分布式环境。
注意:三台机都关闭防火墙和selinux设置为disabled,否则环境搭建好后访问不了50070端口。
二、搭建完全分布式环境
1、新建hadoop用户
这一步不需要,因为是克隆的,我们的机器已经有hadoop用户。
2、配置免密登录
切换到hadoop用户(su hadoop),三台机分别执行如下命令
cd /home/hadoopssh-keygencat /home/hadoop/.ssh/id_rsa.pub
记录cat命令输出每个节点的Key,所有key全部写入到每个节点上的件/home/hadoop/.ssh/authorized_keys中。也就是把每台机的输出合并黏贴到txt中(记得换行),然后都写入/home/hadoop/.ssh/authorized_keys。
echo 'ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDsPbohsUqUYpK4CZncY8QYCOHBew94lk/hdUShjtxP7e4/BO3SQT2byd8Vz4iS1aFYJyodjoItrRtkJ3WPzAB89XC9p5GfiwkHywK0NDji2/NOg7ZNRO3tiPWxhKgJ4td8bAcxEgT3kEIqweoOFFK5nLfBARvp1Zdk5sLxEsnmtsdcxfn0RKDHz90YlXKv1YUm9m5qXi0Jsso7gOpsTCwqmxYxXpX42n1iaAQ88UFbyHCU8kwOO1+zBgIrJ4v7fI2JJ389MJJ73OBXBNP4HUAZqpDxKMcEaCnIPrTRd0735zt0xdwSuESmGp0RI8b/RCLxF6b+ZwoGhLIbO4V5K2wf hadoop@worker1ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDfPJtEbYdnNJxHPQc6STXVYfDqtlXdVyHILqVVgFtqt2Y3meijKS3Fq5cgjL8GsGyIB5ePQd3TVtnSBVzfNWctfCGTbSSSjcc61CYpvq8yMmLTstj1K6sTGWEUUEFENSmcaoFzHSUMQuLvKmOPyR1rGBdSO9IRDnssPOyHd6V8dyfCDeiZXvVgk2WTxwPdur0Bou+LJU73x+8aw4ktpKikBi78r4lFC4qbdWIcJDZ3aJq4CRjcJkSH8SeJ99J3cb0PD8h8YxMl9RF0ugI30A9q38nBYa+7CFsEijl3xjFbOLVuuF0U6Il/aBzUxZVgrc3VFJukDQhFSrjVeTnxv3JP hadoop@worker2ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDPEzIVh/3WJdqfIWPm3RKpFklY+vQiHi3I73AjVZkctHLyUpsE/B4D38pNM2TzsT5kNLlaSRhNWWXYK91klY6CItPZMQxIVIGOyYF1ifG50gniVdtrla7oUiv6J46TUMVnQbLdX8aSDrYHFEmB9Cstffip5HgVEuK2XgwiJ4/7MzasP4zwCXlxtINf7o+AJW3OaumzV6315Xa1AgfEfzLXzkHlreRboQ2i4e19YmoKdOPvjK9XMnDdsFCG+LIK4A9Qkiwbn4CrqLGRWxawUfTcIMEbjFBUrPJiyzKzV1umvpGquxgSQFf/7T4YqQoqzSmq175yRvdTEkhCZH7B8eqr hadoop@worker3' >> ~/.ssh/authorized_keys
当然这里要注意,不能直接黏贴我上面的内容。
3、对免密登录进行测试
这里必须在每一台机都进行一次免密登录的测试,都执行如下命令,否则hadoop启动过程中会提醒用户输入yes,此时将没有人输入。
ssh worker1exitssh worker2exitssh worker3exit
4、配置配置文件
在伪分布式环境中,我们只需要配置core-site.xml和hdfs-site.xml,但是在完全分布式模式下我们需要配置如下四个配置文件,这四个配置文件的作用,会在后面的博文中介绍,这里就不赘述。配置文件所在路径为:/home/hadoop/hadoop-2.8.5/etc/hadoop.
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
这四个配置文件的内容如下:
# core-site.xmlecho '<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>fs.defaultFS</name><value>hdfs://worker1:9000</value><description>设定namenode的主机名及端口</description></property><property><name>io.file.buffer.size</name><value>131072</value><description> 设置缓存大小 </description></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/hadoop-2.8.5/tmp</value><description> 存放临时文件的目录 </description></property><property><name>fs.checkpoint.period</name><value>3600</value><description> 检查点备份日志最长时间 </description></property><property><name>hadoop.security.authorization</name><value>false</value></property></configuration>' > ${HADOOP_HOME}/etc/hadoop/core-site.xml# hdfs-site.xmlecho '<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>3</value><description>分片数量</description></property><property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/name</value><description>命名空间和事务在本地文件系统永久存储的路径</description></property><property><name>dfs.namenode.hosts</name><value>worker1,worker2,worker3</value><description>3个datanode</description></property><property><name>dfs.blocksize</name><value>134217728</value><description>HDFS块大小128M,如果你只有普通网线,就别64M了,没什么用</description></property><property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/data</value><description>DataNode在本地文件系统中存放块的路径</description></property><property><name>dfs.namenode.secondary.http-address</name><value>worker2:50090</value><description>secondary namenode设置到woker2</description></property></configuration>' > ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml# yarn-site.xmlecho '<?xml version="1.0"?><configuration><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value><description>常用类:CapacityScheduler、FairScheduler或者FifoScheduler这里使用公平调度org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</description></property><property><name>yarn.resourcemanager.hostname</name><value>worker1</value><description>指定resourcemanager服务器指向worker1</description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>配置启用日志聚集功能</description></property><property><name>yarn.log-aggregation.retain-seconds</name><value>106800</value><description>配置聚集的日志在HDFS上保存最长时间</description></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>3096</value><description>可使用的物理内存总量</description></property><property><name>yarn.nodemanager.local-dirs</name><value>file://${hadoop.tmp.dir}/nodemanager</value><description>列表用逗号分隔</description></property><property><name>yarn.nodemanager.log-dirs</name><value>file://${hadoop.tmp.dir}/nodemanager/logs</value><description>列表用逗号分隔</description></property><property><name>yarn.nodemanager.log.retain-seconds</name><value>10800</value><description>单位为S</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property></configuration>' > ${HADOOP_HOME}/etc/hadoop/yarn-site.xml# mapred-site.xmlecho '<?xml version="1.0"?><configuration><property><name>mapreduce.framework.name</name><value>yarn</value><description>执行框架设置为Hadoop YARN</description></property><property><name>mapreduce.map.memory.mb</name><value>1024</value><description>maps的资源限制</description></property><property><name>mapreduce.map.java.opts</name><value>-Xmx512M</value><description>maps中jvm child的堆大小</description></property><property><name>mapreduce.reduce.memory.mb</name><value>1024</value><description>reduces的资源限制</description></property><property><name>mapreduce.reduce.java.opts</name><value>-Xmx512M</value><description>reduces jvm child的堆大小</description></property><property><name> mapreduce.jobhistory.address</name><value>worker1:10200</value><description>设置mapreduce的历史服务器安装在worker1机器上</description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>worker1:19888</value><description>历史服务器的web页面地址和端口号</description></property></configuration>' > ${HADOOP_HOME}/etc/hadoop/mapred-site.xml
大家需要注意的是修改core-site.xml中的hadoop.tmp.dir和节点名称数量,这里设置的分片是3,因为有三台机器,之前伪分布式设置为1因为只有1台机器。
这里我采取的配置方式是在worker1上配置好,然后用scp命令复制到worker2和worker3中,在worker1撒红果果执行上面的命令配置好配置文件,然后进入到配置文件目录:
cd /home/hadoop/hadoop-2.8.5/etc/hadoop
执行scp命令传输文件:
scp core-site.xml hadoop@worker2:/home/hadoop/hadoop-2.8.5/etc/hadoopscp hdfs-site.xml hadoop@worker2:/home/hadoop/hadoop-2.8.5/etc/hadoopscp yarn-site.xml hadoop@worker2:/home/hadoop/hadoop-2.8.5/etc/hadoopscp mapred-site.xml hadoop@worker2:/home/hadoop/hadoop-2.8.5/etc/hadoopscp core-site.xml hadoop@worker3:/home/hadoop/hadoop-2.8.5/etc/hadoopscp hdfs-site.xml hadoop@worker3:/home/hadoop/hadoop-2.8.5/etc/hadoopscp yarn-site.xml hadoop@worker3:/home/hadoop/hadoop-2.8.5/etc/hadoopscp mapred-site.xml hadoop@worker3:/home/hadoop/hadoop-2.8.5/etc/hadoop
这里还有一个配置文件也需要配置,那就是slaves,大家也可以参照上面的模式,在worker1上执行,然后scp到worker2和worker3,也可以在每一台机器上执行如下命令:
echo 'worker1worker2worker3' > ${HADOOP_HOME}/etc/hadoop/slaves
5、格式化
原本需要在每一台机器上建立如下文件夹,也就是core-site.xml中配置的hadoop.tmp.dir,但是之前搭建伪分布式的时候已经建立好了,这里只需要去清除数据即可。三台机分别执行如下命令:
cd ${HADOOP_HOME}/tmprm -rf ./*
记得执行rm -rf命令的时候注意路径是否正确。
接下来在worker1上执行格式化命令:
hdfs namenode -format
三、启动和测试
1、启动
上面已经配置好了配置文件以及格式化,所以这里直接在worker1上执行如下命令启动即可。
start-dfs.shstart-yarn.shyarn-daemon.sh start resourcemanagermr-jobhistory-daemon.sh start historyserver # 开启历史服务器才能在Web中查看任务运行情况
可以查看对应的日志是否启动成功,因为配置文件如果有问题,比如格式写错什么的会在日志中打印出来的。如果有jps命令可以查看每一台机的节点,会发现:
worker1有:NameNode、DataNode、ResourceManager、NodeManager、JobHistoryServer
worker2有:DataNode、SecondaryNameNode、NodeManager
worker3有:DataNode、NodeManager
worker2中的SecondaryNameNode是配置文件hdfs-site.xml有对应:dfs.namenode.secondary.http-address。
当然我这里不知道为什么没有jps命令,我是用ps -ef|grep java命令查看的。
之前只安装了jdk的运行环境其实继续安装开发环境就可以了:
yum install java-1.8.0-openjdk-devel.x86_64
2、测试
上面一步启动后,浏览器访问http://192.168.157.3:50070 就可进入到页面中可以看到有三个分片,测试方式直接跟上一篇伪分布的方式测试即可。在worker1上新建一个文件,然后上传到根目录:
mkdir lwh.txthdfs dfs -put lwh.txt /
然后就可以看到上传成功;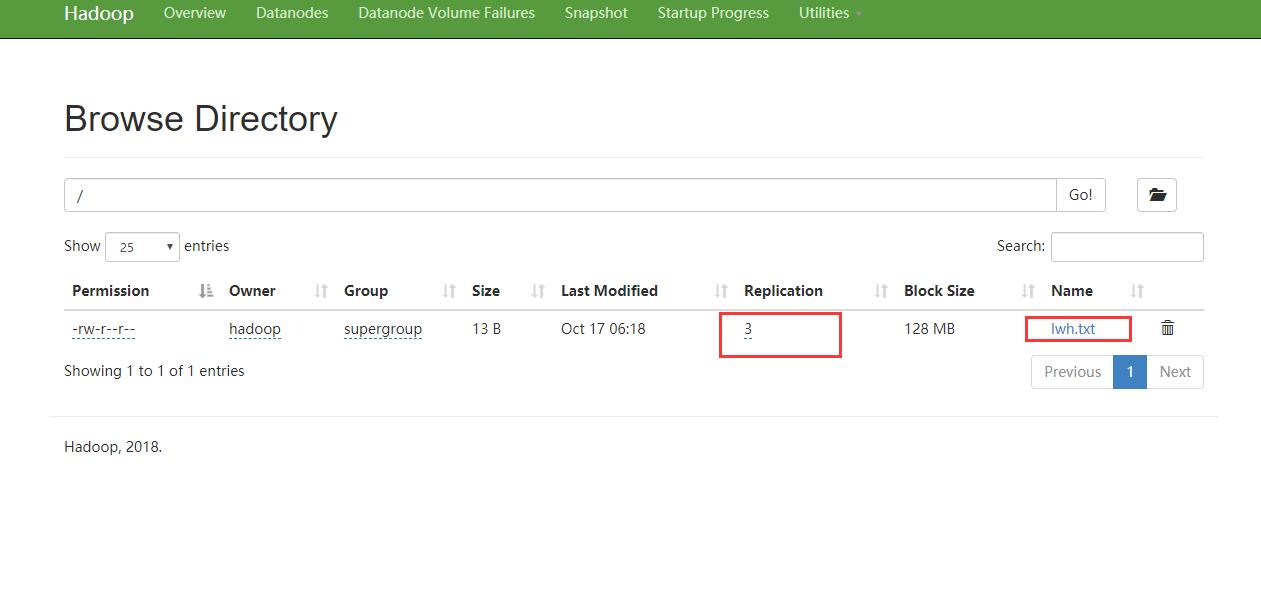
yarn的访问端口是8088
结束!
