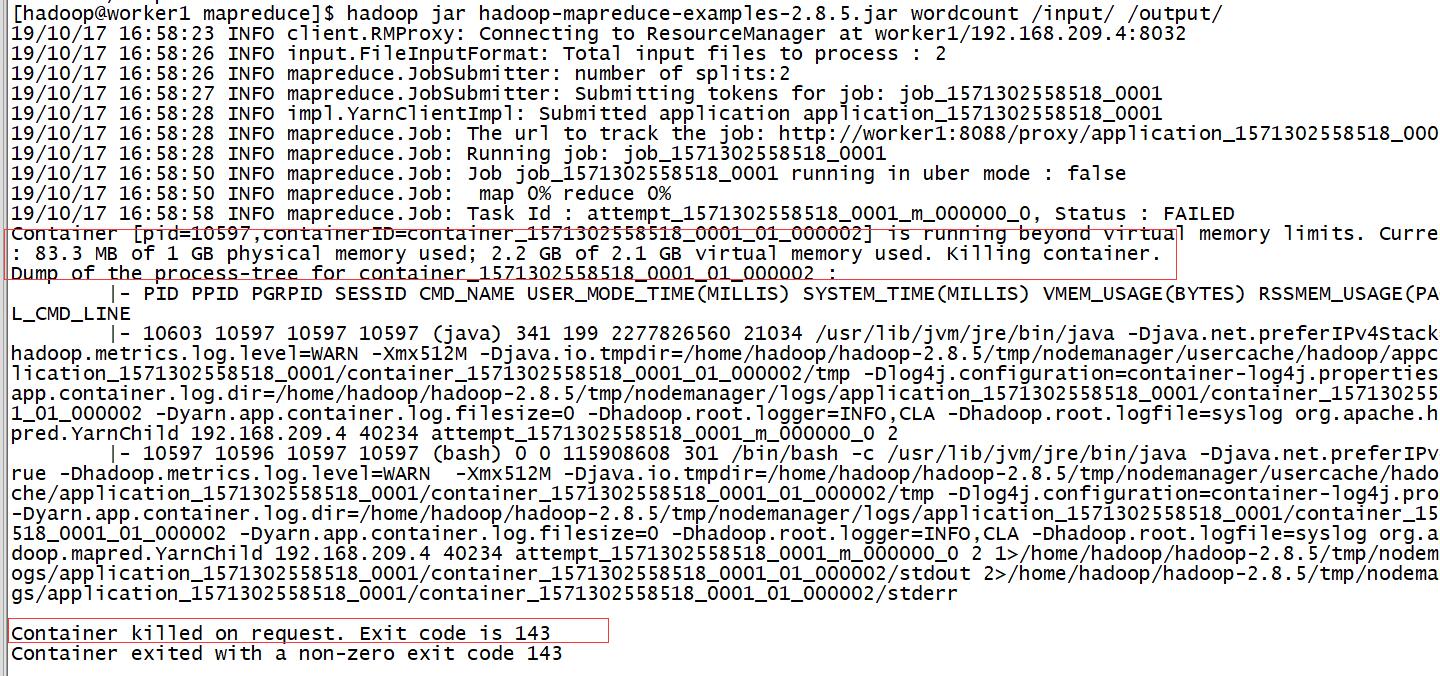






在启动hadoop程序的时候,可能会报该错误,具体如下:
是hadoop 在 yarn 上运行时报的虚拟内存错误,或者是物理内存不够错误。
错误原因
Current usage: 83.3 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container.
异常分析
- 83.3MB: 任务所占的物理内存
- 1GB 是mapreduce.map.memory.mb 设置的
- 2.2G 是程序占用的虚拟内存: 什么是虚拟内存以及和物理内存的关系
- 2.1GB 是mapreduce.map.memory.db 乘以 yarn.nodemanager.vmem-pmem-ratio 得到的
其中yarn.nodemanager.vmem-pmem-ratio 是 虚拟内存和物理内存比例,在yarn-site.xml中设置,默认是2.1, , 所以 1*2.1 = 2.1GB
很明显,container占用了2.2G的虚拟内存,但是分配给container的却只有2.1GB。所以kill掉了这个container
上面只是map中产生的报错,当然也有可能在reduce中报错,如果是reduce中,那么就是mapreduce.reduce.memory.db * yarn.nodemanager.vmem-pmem-ratio
解决办法
1、取消虚拟内存的检查
在yarn-site.xml或者程序中中设置yarn.nodemanager.vmem-check-enabled为false
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value><description>Whether virtual memory limits will be enforced for containers.</description></property>
除了虚拟内存超了,也有可能是物理内存超了,同样也可以设置物理内存的检查为false: yarn.nodemanager.pmem-check-enabled
个人认为这种办法并不太好,如果程序有内存泄漏等问题,取消这个检查,可能会导致集群崩溃。
2、增大mapreduce.map.memory.mb 或者 mapreduce.reduce.memory.mb
应该优先考虑这种办法,这种办法不仅仅可以解决虚拟内存,或许大多时候都是物理内存不够了,这个办法正好适用.
我这边是修改了mapred-site.xml的上面两个配置,改为了2048.
<property><name>mapreduce.map.memory.mb</name><value>2048</value><description>maps的资源限制</description></property><property><name>mapreduce.reduce.memory.mb</name><value>2048</value><description>reduces的资源限制</description></property>
这样子2*2.1=4.2>2.2 够用了。同步配置文件重启后果然可以了。
3、适当增大yarn.nodemanager.vmem-pmem-ratio的大小,一个物理内存增大多个虚拟内存, 但是这个参数也不能太离谱
本质还是围绕:mapreduce.reduce.memory.db * yarn.nodemanager.vmem-pmem-ratio来做处理。
