





在博文最小化CentOS7系统安装完全分布式hadoop-2.8.5中我搭建好了完全分布式集群,现在可以用hadoop自带的程序测试下。
1、在如下目录下新建两个文件
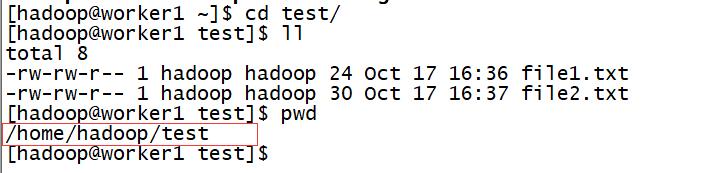
file1.txt
Hello javaHello world
file2.txt
Hello hadoopHello wordcount
2、在HDFS中创建一个input文件夹
hdfs dfs -mkdir /input
3、把刚才两个文件上传到input目录下
hdfs dfs -put ./*.txt /input
4、运行wordcount程序
先进入这个程序所在的目录下:
cd /home/hadoop/hadoop-2.8.5/share/hadoop/mapreduce
然后执行程序
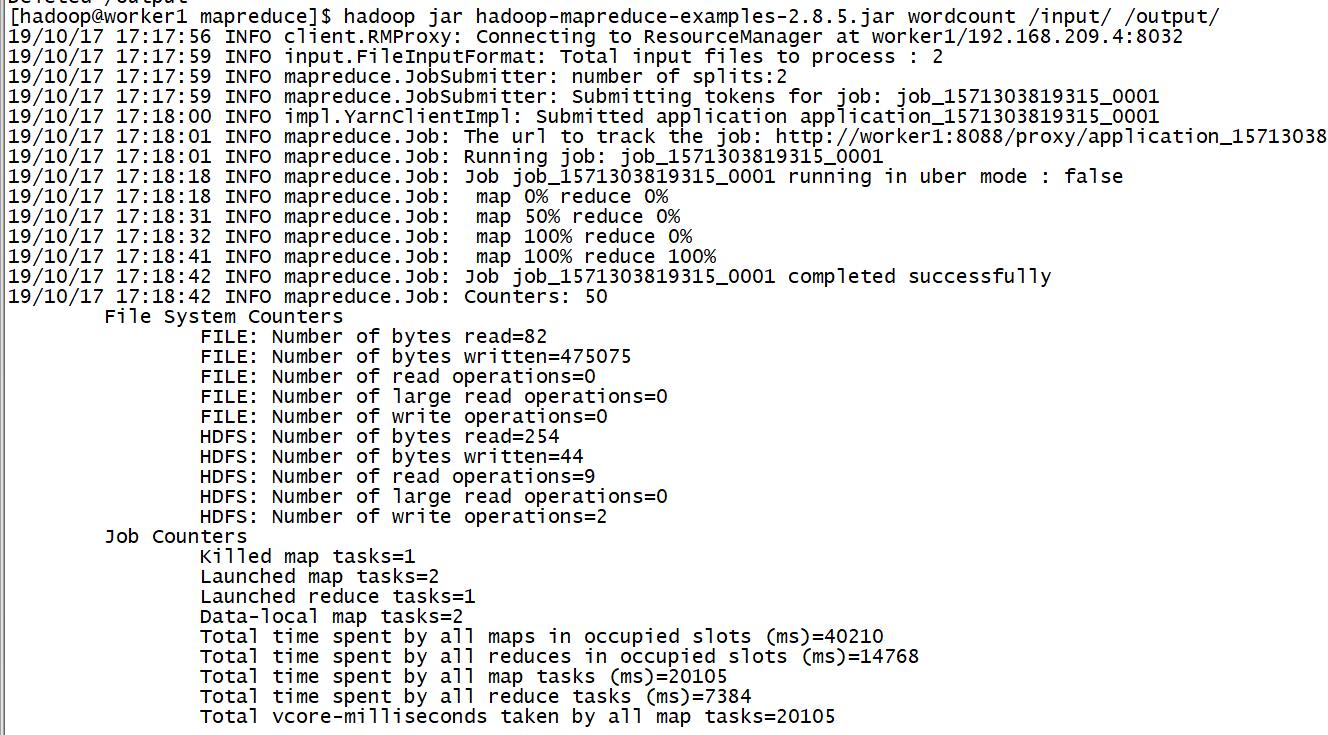
hadoop jar hadoop-mapreduce-examples-2.8.5.jar wordcount /input/ /output/
注:output文件夹是不存在的,使用上述命令后自动创建的。如果此文件夹存在会报错如下错误: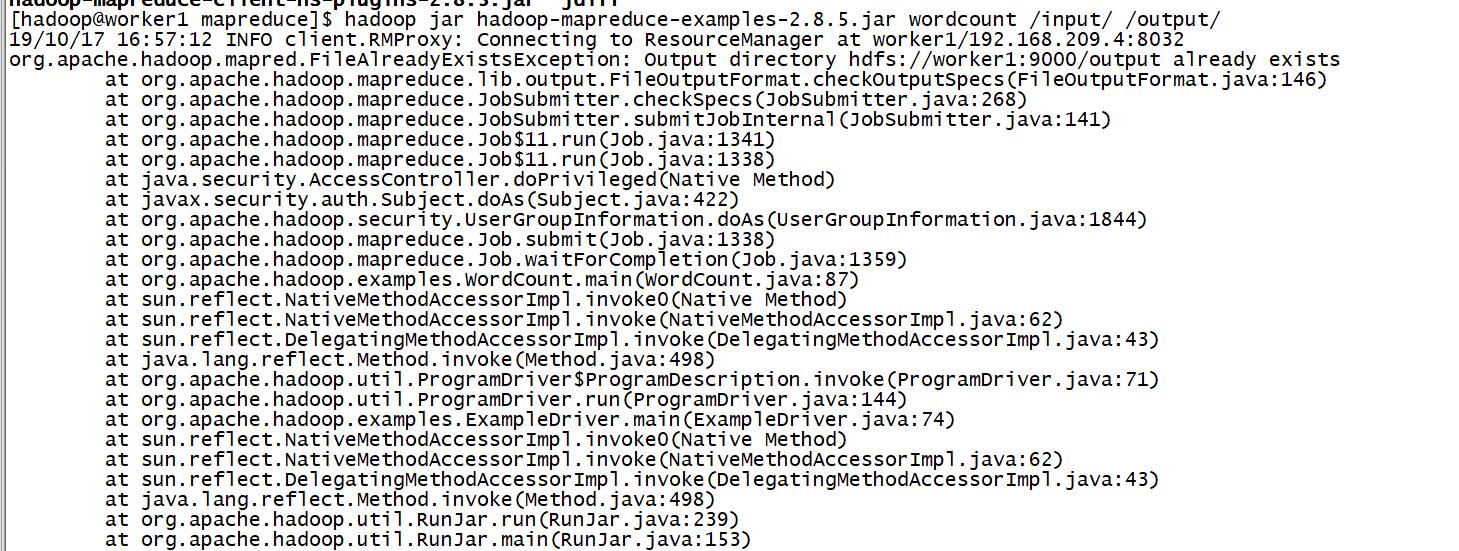
若是配置不当也可能会报我这篇博文描述的错误:Container killed on request. Exit code is 143
运行正常的截图如下: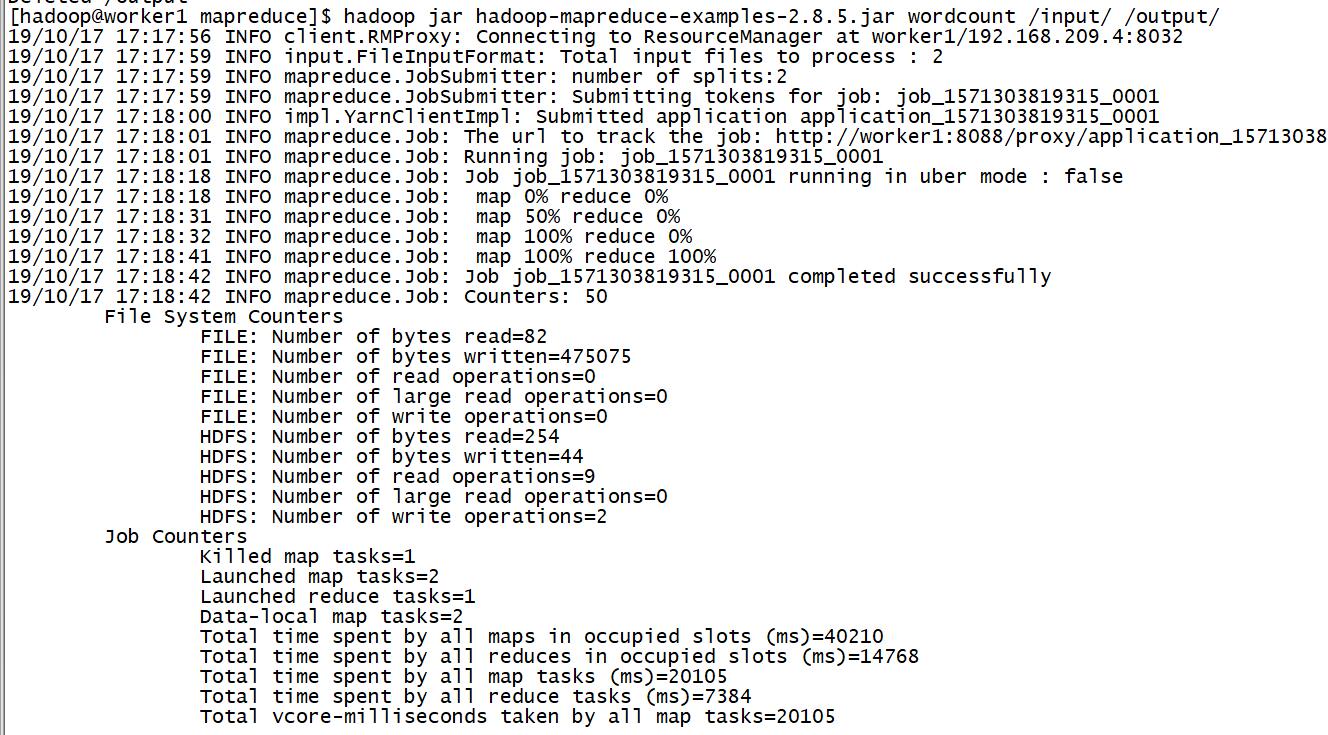
查看结果:
hdfs dfs -cat /output/*

结束!
