





给定任意的HDFS 的输入目录,其内部数据为“f a c d e……”等用空格字符分隔的字符串,通过使用MapReduce 计算框架来统计以空格分隔的每个单词出现的频率,输出结果如
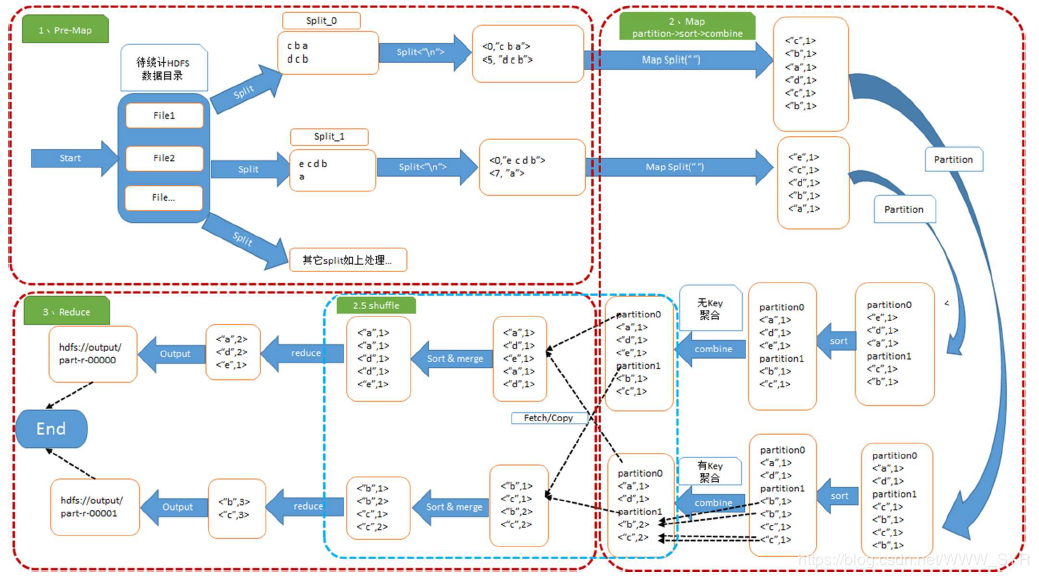
MapReduce 将作业的整个运行过程分为两个阶段:Map 阶段Reduce 阶段。
MapReduce过程:
1)首先从hdfs上读取文件,将文件进行切片,每个切片对应一个map任务;
2)之后数据经过map处理后进行分区,分区的个数与reduce任务有关系;
3)经过分区以后进入map的shuffle阶段,在此阶段要进行排序。然后进入reduce的shuffle阶段,fetch© Map的输出数据,此阶段要进行sort和merge,将数据进行排序和合并到一个文件中;
4)最后经过group后,进行reduce处理,然后将数据保存在hdfs上。
sort&merge:排序和将所有的小文件合并成一个大文件;
group过程:将相同的key对应的val分组成iterable。
通常我们把从Mapper 输出数据到Reduce 读取数据之间的过程称之为shuffle。
总结:
map过程实际上就是将一组键值(k1,v1)对打散成一组新的键值对(k2,v2);
reduce是将排序好的键值对,按照相同的键k2合并成一个(k2,value_list)。
