





MapReduce将作业job的整个运行过程分为两个阶段:Map阶段和Reduce阶段。按照时间顺序包括:输入分片(input split)、map阶段、combiner阶段、shuffle阶段和reduce阶段。系统执行排序、将map输出作为输入传给reducer的过程称为shuffle(shuffle是MapReducer的心脏)
Map阶段由一定数量的 Map Task组成
- 输入数据格式解析: InputFormat
- 输入数据处理: Mapper
- 本地合并: Combiner(local reduce)
- 数据分组: Partitioner
Reduce阶段由一定数量的 Reduce Task组成
- 数据远程拷贝
- 数据按照key排序
- 数据处理: Reducer
- 数据输出格式: OutputFormat
1、流程简介
各个map函数对所划分的数据并行处理,从不同的输入数据产生不同的中间结果输出
各个reduce也各自并行计算,各自负责处理不同的中间结果数据集合进行reduce处理之前,必须等到所有的map函数做完
在进入reduce前需要有一个同步障(barrier) ,这个阶段也负责对map的中间结果数据进行收集整理(aggregation & shuffle)处理,以便reduce更有效地计算最终结果, 最终汇总所有reduce的输出结果即可获得最终结果
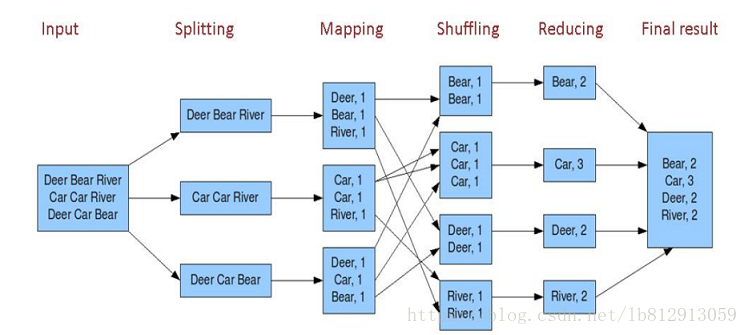
第一步:假设一个文件有三行英文单词作为 MapReduce 的Input(输入)这里经过 Splitting 过程把文件分割为3块。分割后的3块数据就可以并行处理,每一块交给一个 map 线程处理。第二步:每个 map 线程中,以每个单词为key,以1作为词频数value,然后输出。第三步:每个 map 的输出要经过 shuffling(混洗),将相同的单词key放在一个桶里面,然后交给 reduce 处理。第四步:reduce 接受到 shuffling 后的数据, 会将相同的单词进行合并,得到每个单词的词频数,最后将统计好的每个单词的词频数作为输出结果。
上述就是 MapReduce 的大致流程,前两步可以看做 map 阶段,后两步可以看做 reduce 阶段。
2、输入分片与类型
MapReduce将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每一个split分配一个mapTask并行实例处理。
输入分片(split)与map对应,是每个map处理的唯一单位。每个分片包括多条记录,每个记录都有对应键值对。
输入切片的接口:InputSplit接口(不需要开发人员直接处理,由InputFormat创建)。
输入分片(input split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组,输入分片(input split)往往和hdfs的block(块)关系很密切,存储位置供MapReduce使用以便将map任务尽量放在分片数据附近,而长度用来排序分片,以便优化处理最大的分片,从而最小化作业运行时间。
假如我们设定hdfs的块的大小是64mb,如果我们输入有三个文件,大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片(input split),65mb则是两个输入分片(input split)而127mb也是两个输入分片(input split),换句话说我们如果在map计算前做输入分片调整,例如合并小文件,那么就会有5个map任务将执行,而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点。
输入类型
FileInputFormat类: FileInputFormat 是所有使用文件作为其数据源的 InputFormat 实现的基类。它提供了两个功能:一个定义哪些文件包含在一个作业的输入中;一个为输入文件生成分片的实现。把分片分割成记录的作业由其子类来完成。
TextlnputFormat类: TextInputFormat 是默认的 InputFormat。每条记录是一行输入。键是 LongWritable 类型,存储该行在整个文件中的字节偏移量。值是这行的内容,不包括任何行终止符(换行符和回车符),它是 Text 类型的。但是输入分片和HDFS块之间可能不能很好的匹配,出现跨块的情况。
KeyValueTextlnputFormat类:TextInputFormat 的键,即每一行在文件中的字节偏移量,通常并不是特别有用。通常情况下,文件中的每一行是一个键/值对,使用某个分界符进行分隔,比如制表符。例如 以下由 Hadoop 默认 OutputFormat(即 TextOutputFormat)产生的输出。如果要正确处理这类 文件,KeyValueTextInputFormat 比较合适。可以通过 key.value.separator.in.input.line 属性来指定分隔符。它的默认值是一个制表符。
NLineInputFormat类: 与TextInputFormat一样,键是文件中行的字节偏移量,值是行本身。主要是希望mapper收到固定行数的输入。
MultipleInputs多种输入:MultipleInputs类处理多种格式的输入,允许为每个输入路径指定InputFormat和Mapper。两个mapper的输出类型是一样的,所以reducer看到的是聚集后的map输出,并不知道输入是不同的mapper产生的。
重载版本:addInputPath(),没有mapper参数,主要支持多种输入格式只有一个mapper。

3、Map与Reduce的个数
Map任务的个数
读取数据产生多少个Mapper?
Mapper数据过大的话,会产生大量的小文件,过多的Mapper创建和初始化都会消耗大量的硬件资源 ,Mapper数太小,并发度过小,Job执行时间过长,无法充分利用分布式硬件资源。
Mapper数量由什么决定?
(1)输入文件数目(2)输入文件的大小(3)配置参数 这三个因素决定的。
输入的目录中文件的数量决定多少个map会被运行起来,应用针对每一个分片运行一个map,一般而言,对于每一个输入的文件会有一个map split。如果输入文件太大,超过了hdfs块的大小(128M)那么对于同一个输入文件我们会有多余2个的map运行起来。
会有一个比例进行运算来进行切片,为了减少资源的浪费
例如一个文件大小为260M,在进行MapReduce运算时,会首先使用260M/128M,得出的结果和1.1进行比较
大于则切分出一个128M作为一个分片,剩余132M,再次除以128,得到结果为1.03,小于1.1
则将132作为一个切片,即最终260M被切分为两个切片进行处理,而非3个切片。
reduce任务的个数
Reduce任务是一个数据聚合的步骤,数量默认为1。而使用过多的Reduce任务则意味着复杂的shuffle,并使输出文件的数量激增。
一个job的ReduceTasks数量是通过mapreduce.job.reduces参数设置也可以通过编程的方式,调用Job对象的setNumReduceTasks()方法来设置一个节点Reduce任务数量上限由mapreduce.tasktracker.reduce.tasks.maximum设置(默认2)。可以采用以下探试法来决定Reduce任务的合理数量:1.每个reducer都可以在Map任务完成后立即执行:0.95 * (节点数量 * mapreduce.tasktracker.reduce.tasks.maximum)2.较快的节点在完成第一个Reduce任务后,马上执行第二个:1.75 * (节点数量 * mapreduce.tasktracker.reduce.tasks.maximum)
4、小文件合并
Mapper是基于文件自动产生的,如何自己控制Mapper的个数?需要通过参数的控制来调节Mapper的个数。减少Mapper的个数就要合并小文件,这种小文件有可能是直接来自于数据源的小文件,也可能是Reduce产生的小文件。
设置合并器:(set都是在hive脚本,也可以配置Hadoop)设置合并器本身:set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;set hive.merge.mapFiles=true;set hive.merge.mapredFiles=true;set hive.merge.size.per.task=256000000;//每个Mapper要处理的数据,就把上面的5M10M……合并成为一个一般还要配合一个参数:set mapred.max.split.size=256000000 // mapred切分的大小set mapred.min.split.size.per.node=128000000//低于128M就算小文件,数据在一个节点会合并,在多个不同的节点会把数据抓过来进行合并。Hadoop中的参数:可以通过控制文件的数量控制mapper数量mapreduce.input.fileinputformat.split.minsize(default:0),小于这个值会合并mapreduce.input.fileinputformat.split.maxsize 大于这个值会切分
5、Map阶段
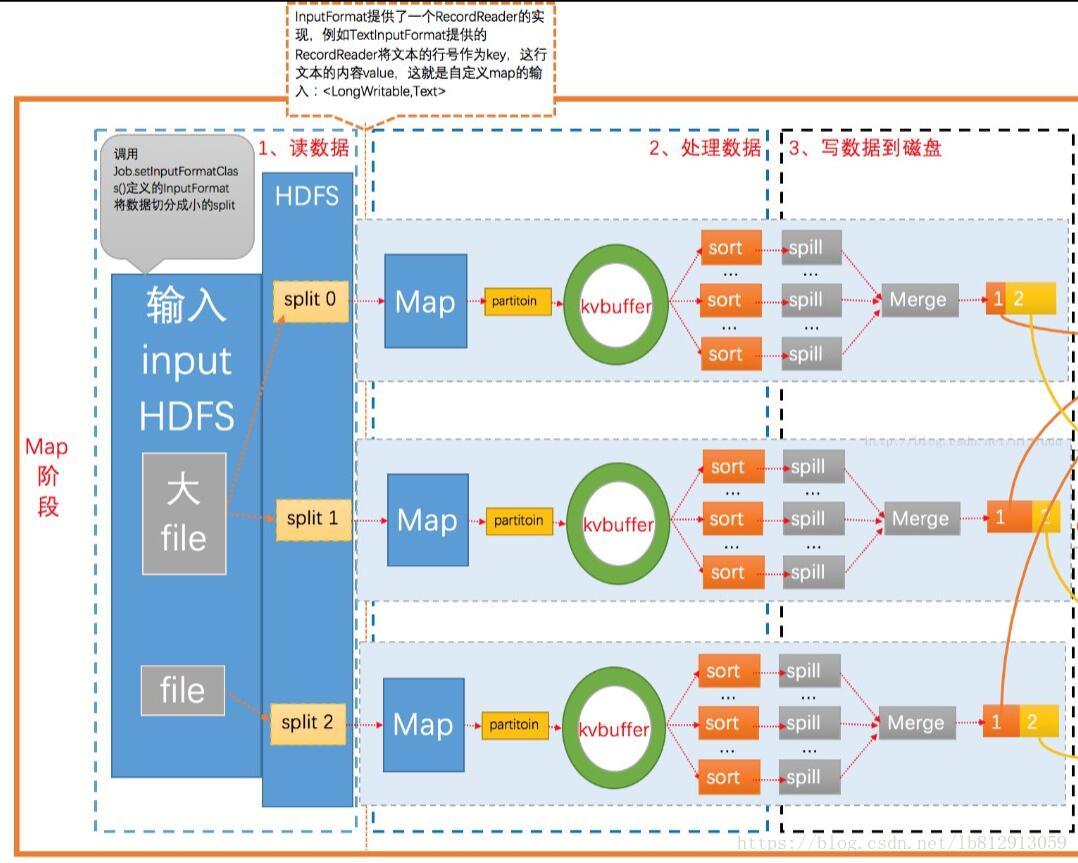
Map阶段是由一定数量的 Map Task组成。这些Map Task可以同时运行,每个Map Task又是由以下三个部分组成。
1. InputFormat输入数据格式解析组件:因为不同的数据可能存储的数据格式不一样,这就需要有一个InputFormat组件来解析这些数据的存放格式,默认情况下,它提供了一个TextInputFormat文本文件输入格式来解释数据格式。 它会将文件的每一行解释成(key,value),key代表每行偏移量,value代表每行数据内容,通常情况我们不需要自定义InputFormat,因为MapReduce提供了多种支持不同数据格式InputFormat的实现 .
2. Mapper输入数据处理:这个Mapper是必须要实现的,因为根据不同的业务对数据有不同的处理。
3. Partitioner数据分组:
Mapper数据处理之后输出之前,输出key会经过Partitioner分组或者分桶选择不同的reduce,默认的情况下Partitioner会对map输出的key进行hash取模。
比如有6个ReduceTask,它就是模6,如果key的hash值为0,就选择第0个ReduceTask(为1,选Reduce Task1)。这样不同的map对相同单词key,它的hash值取模是一样的,所以会交给同一个reduce来处理。
6、Reduce阶段
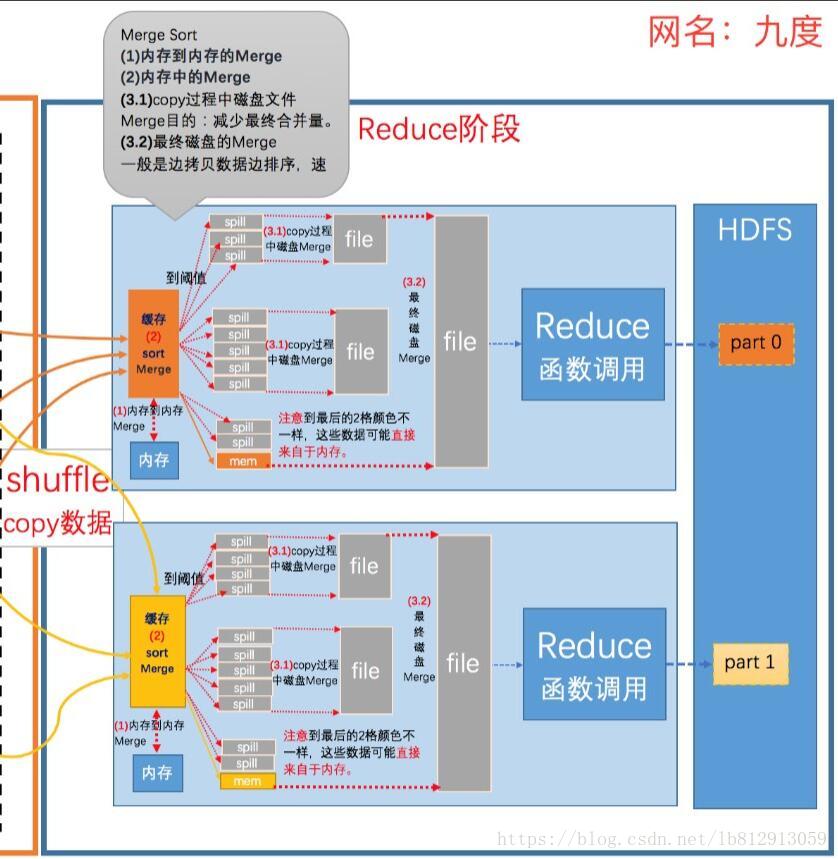
1.数据运程拷贝
Reduce Task要远程拷贝每个map处理的结果,从每个map中读取一部分结果,每个Reduce Task拷贝哪些数据,是由上面Partitioner决定的。
2.数据按照key排序
Reduce Task读取完数据后,要按照key进行排序,相同的key被分到一组,交给同一个Reduce Task处理
3.Reducer数据处理
以WordCount为例,相同的单词key分到一组,交个同一个Reducer处理,这样就实现了对每个单词的词频统计。
4.OutputFormat数据输出格式
Reducer统计的结果将按照OutputFormat格式输出(默认情况下的输出格式为TextOutputFormat)
版权声明:本文为CSDN博主「雾幻」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lb812913059/article/details/79898768
