





Reduce端的shuffle主要包括三个阶段,copy,sort(merge),reduce
Map的输出文件放置在运行MapTask的NodeManager的本地磁盘上,它是运行ReduceTask的TaskTracker所需要的输入数据,但是Reduce输出不是这样的,它一般写到HDFS中(Reduce阶段)。
1、Copy阶段
Reduce进程启动一些数据copy线程,通过HTTP方式请求MapTask所在的NodeManager以获取输出文件。
NodeManager需要为分区文件运行reduce任务。并且reduce任务需要集群上若干个map任务的map输出作为其特殊的分区文件。而每个map任务的完成时间可能不同,因此只要有一个任务完成,reduce任务就开始复制其输出。
reduce任务有少量复制线程,因此能够并行取得map输出。默认线程数为5,但这个默认值可以通过mapreduce.reduce.shuffle.parallelcopies属性进行设置。
【Reducer如何知道自己应该处理哪些数据呢?】
因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每个Reducer会处理一个或者多个partition。
【reducer如何知道要从哪台机器上去的map输出呢?】
map任务完成后,它们会使用心跳机制通知它们的application master、因此对于指定作业,application master知道map输出和主机位置之间的映射关系。reducer中的一个线程定期询问master以便获取map输出主机的位置。知道获得所有输出位置。
由于reducer可能失败,因此tasktracker并没有在第一个reducer检索到map输出时就立即从磁盘上删除它们。相反,tasktracker会等待,直到jobtracker告知它可以删除map输出,这是作业完成后执行的。
1、由于job的每一个map都会根据reduce(n)数将数据分成map 输出结果分成n个partition,所以map的中间结果中是有可能包含每一个reduce需要处理的部分数据的。所以,为了优化reduce的执行时间,hadoop中是等job的第一个map结束后,所有的reduce就开始尝试从完成的map中下载该reduce对应的partition部分数据,因此map和reduce是交叉进行的,其实就是shuffle。Reduce任务通过HTTP向各个Map任务拖取(下载)它所需要的数据(网络传输),Reducer是如何知道要去哪些机器取数据呢?一旦map任务完成之后,就会通过常规心跳通知应用程序的Application Master。reduce的一个线程会周期性地向master询问,直到提取完所有数据(如何知道提取完?)数据被reduce提走之后,map机器不会立刻删除数据,这是为了预防reduce任务失败需要重做。因此map输出数据是在整个作业完成之后才被删除掉的。
2、reduce进程启动数据copy线程(Fetcher),通过HTTP方式请求maptask所在的TaskTracker获取maptask的输出文件。由于map通常有许多个,所以对一个reduce来说,下载也可以是并行的从多个map下载,那到底同时到多少个Mapper下载数据??这个并行度是可以通过mapreduce.reduce.shuffle.parallelcopies(default5)调整。默认情况下,每个Reducer只会有5个map端并行的下载线程在从map下数据,如果一个时间段内job完成的map有100个或者更多,那么reduce也最多只能同时下载5个map的数据,所以这个参数比较适合map很多并且完成的比较快的job的情况下调大,有利于reduce更快的获取属于自己部分的数据。 在Reducer内存和网络都比较好的情况下,可以调大该参数;
3、reduce的每一个下载线程在下载某个map数据的时候,有可能因为那个map中间结果所在机器发生错误,或者中间结果的文件丢失,或者网络瞬断等等情况,这样reduce的下载就有可能失败,所以reduce的下载线程并不会无休止的等待下去,当一定时间后下载仍然失败,那么下载线程就会放弃这次下载,并在随后尝试从另外的地方下载(因为这段时间map可能重跑)。reduce下载线程的这个最大的下载时间段是可以通过mapreduce.reduce.shuffle.read.timeout(default180000秒)调整的。如果集群环境的网络本身是瓶颈,那么用户可以通过调大这个参数来避免reduce下载线程被误判为失败的情况。一般情况下都会调大这个参数,这是企业级最佳实战。
2、sort(merge)
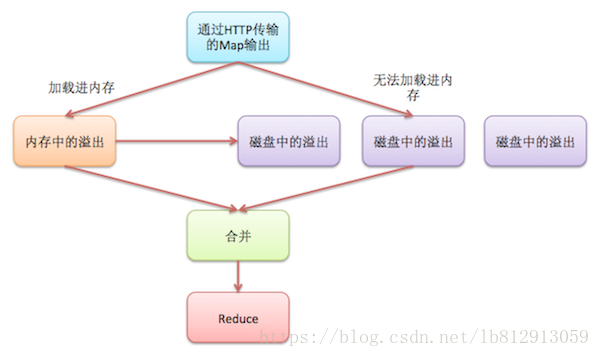
Copy 过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比 map 端的更为灵活,它基于 JVM 的 heap size 设置,因为 Shuffle 阶段 Reducer 不运行,所以应该把绝大部分的内存都给 Shuffle 用。
Copy过来的数据会先放入内存缓冲区中,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。与map端的溢写类似,在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会化简压缩合并的map输出。Reduce的内存缓冲区可通过mapred.job.shuffle.input.buffer.percent配置,默认是JVM的heap size的70%。内存到磁盘merge的启动门限可以通过mapred.job.shuffle.merge.percent配置,默认是66%。
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程,采取的排序方法跟map阶段不同,因为每个map端传过来的数据是排好序的,因此众多排好序的map输出文件在reduce端进行合并时采用的是归并排序,针对键进行归并排序。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。
3、reduce
当一个reduce任务完成全部的复制和排序后,就会针对已根据键排好序的Key构造对应的Value迭代器。这时就要用到分组,默认的根据键分组,自定义的可是使用 job.setGroupingComparatorClass()方法设置分组函数类。对于默认分组来说,只要这个比较器比较的两个Key相同,它们就属于同一组,它们的 Value就会放在一个Value迭代器,而这个迭代器的Key使用属于同一个组的所有Key的第一个Key。
在reduce阶段,reduce()方法的输入是所有的Key和它的Value迭代器。此阶段的输出直接写到输出文件系统,一般为HDFS。如果采用HDFS,由于NodeManager也运行数据节点,所以第一个块副本将被写到本地磁盘。
1、当reduce将所有的map上对应自己partition的数据下载完成后,reducetask真正进入reduce函数的计算阶段。由于reduce计算时同样是需要内存作为buffer,可以用mapreduce.reduce.input.buffer.percent(default 0.0)(源代码MergeManagerImpl.java:674行)来设置reduce的缓存。
这个参数默认情况下为0,也就是说,reduce是全部从磁盘开始读处理数据。如果这个参数大于0,那么就会有一定量的数据被缓存在内存并输送给reduce,当reduce计算逻辑消耗内存很小时,可以分一部分内存用来缓存数据,可以提升计算的速度。所以默认情况下都是从磁盘读取数据,如果内存足够大的话,务必设置该参数让reduce直接从缓存读数据,这样做就有点Spark Cache的感觉。
2、Reduce在这个阶段,框架为已分组的输入数据中的每个键值对对调用一次 reduce(WritableComparable,Iterator, OutputCollector, Reporter)方法。Reduce任务的输出通常是通过调用 OutputCollector.collect(WritableComparable,Writable)写入文件系统的。
