





Shuffle阶段是指从Map的输出开始,包括系统执行排序以及传送Map输出到Reduce作为输入的过程。Sort阶段是指对Map端输出的Key进行排序的过程。不同的Map可能输出相同的Key,相同的Key必须发送到同一个Reduce端处理。Shuffle阶段可以分为Map端的Shuffle和Reduce端的Shuffle。
shuffle是MapReduce的心脏,属于不断被优化和改进的代码库的一部分。

1、Map端shuffle
map端的shuffle包括环形内存缓冲区执行溢出写,partition,sort,combiner,生成溢出写文件,合并。
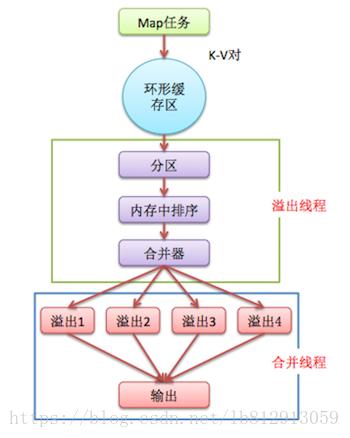
Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。map函数开始产生输出时并非简单地将它输出到磁盘。因为频繁的磁盘操作会导致性能严重下降。它的处理过程更复杂,数据首先写到内存中的一个缓冲区,并做一些预排序,以提升效率。
每个map任务都有一个环形内存缓冲区,用于存储任务的输出(默认大小100MB,mapreduce.task.io.sort.mb调整),被缓冲的K-V对记录已经被序列化,但没有排序。而且每个K-V对都附带一些额外的审计信息。
一旦缓冲内容达到阈值(mapreduce.map.io.sort.spill.percent,默认0.80,或者80%),就会创建一个溢出写文件,同时开启一个后台线程把数据溢出写(spill)到本地磁盘中。溢出写过程按轮询方式将缓冲区中的内容写到mapreduce.cluster.local.dir属性指定的目录中。
在写磁盘之前,线程首先根据数据最终要传递到的Reducer把数据划分成相应的分区(partition),输出key会经过Partitioner分组或者分桶选择不同的reduce。默认的情况下Partitioner会对map输出的key进行hash取模,比如有6个ReduceTask,它就是模6,如果key的hash值为0,就选择第0个ReduceTask(为1,选Reduce Task1)。这样不同的map对相同单词key,它的hash值取模是一样的,所以会交给同一个reduce来处理。目的是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。
然后在每个分区中,后台线程将数据按Key进行排序(排序方式为快速排序)。接着运行combiner在本地节点内存中将每个Map任务输出的中间结果按键做本地聚合(如果设置了的话),可以减少传递给Reducer的数据量。可以通过setCombinerClass()方法来指定一个作业的combiner。当溢出写文件生成数至少为3时(mapreduce.map.combine.minspills属性设置),combiner函数就会在它排序后的输出文件写到磁盘之前运行。
在写磁盘过程中,另外的20%内存可以继续写入数据,两种操作互不干扰,但如果在此期间缓冲区被填满,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再执行写入内存。
在map任务写完其最后一个输出记录之后,可能产生多个spill文件,在每个Map任务完成前,溢出写文件被合并成一个索引文件和数据文件(多路归并排序)(Sort阶段)。一次最多合并多少流由io.sort.factor控制,默认为10。至此,Map端的shuffle过程就结束了。
溢出写文件归并完毕后,Map将删除所有的临时溢出写文件,并告知NodeManager任务已完成,只要其中一个MapTask完成,ReduceTask就开始复制它的输出(Copy阶段分区输出文件通过http的方式提供给reducer)
partition如何分组
一个输出元组的分割指数是多少?(分区的指数)在Mapper.Context.write()内部被指定:
partitionIdx = (key.hashCode() & Integer.MAX_VALUE) % numReducerspartitionID的值=(键的哈希值 按位与 int的最大值)%reduce的数量
随着输出元组以元数据的形式保存在环形缓冲区,可通过配置mapreduce.job.partitioner.class参数自己定制partitioner。
combiner
如果指定了Combiner,可能在两个地方被调用:
1.当为作业设置Combiner类后,缓存溢出线程将缓存存放到磁盘时,就会调用;
2.缓存溢出的数量超过mapreduce.map.combine.minspills(默认3)时,在缓存溢出文件合并的时候会调用
combiner可以在输入上反复运行,但并不影响最终结果。它的本质也是一个Reducer。其目的是对将要写入到磁盘上的文件先进行一次处理,这样使得map输出结果更加紧凑,减少写到磁盘的数据。如果只有1或2个溢出写文件,那么由于map输出规模减少,因此不会为该map输出再次运行combiner。
combiner操作是有风险的,使用它的原则是combiner的输入不会影响到reduce计算的最终输入
例如:如果计算只是求总数,最大最小值可以使用combiner,但是做平均值计算使用combiner的话,最终的reduce计算结果就会出错。
压缩
写磁盘时压缩map端的输出,因为这样会让写磁盘的速度更快,节约磁盘空间,并减少传给reducer的数据量。默认情况下,输出是不压缩的(将mapreduce.map.output.compress设置为true即可启动)
版权声明:本文为CSDN博主「雾幻」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lb812913059/article/details/79899644
